Saliency-Informed Spatio-Temporal Vector of Locally Aggregated Descriptors and Fisher Vectors for Visual Action Recognition
Abstract
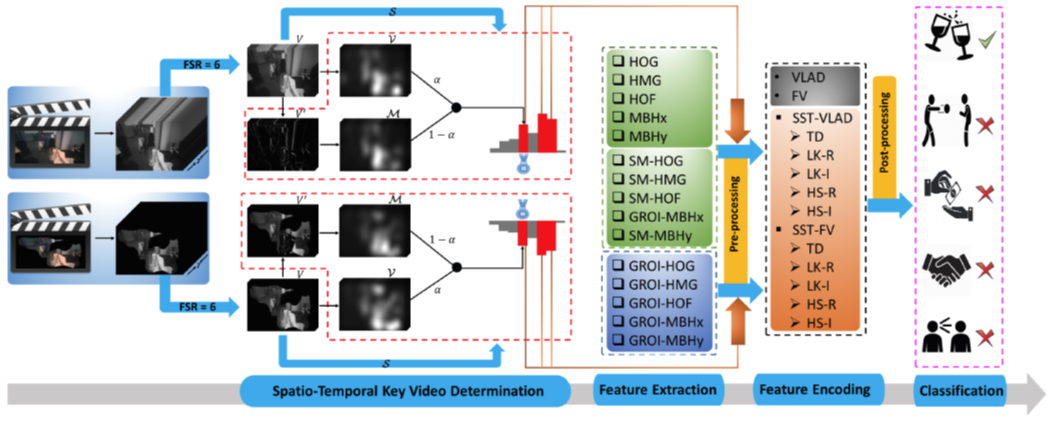
Feature encoding has been extensively studied for the task of visual action recognition (VAR). The recently proposed super vector-based encoding methods, such as the Vector of Locally Aggregated Descriptors (VLAD) and the Fisher Vectors (FV), have significantly improved the recognition performance. Despite of the success, they still struggle with the superfluous information that presents during the training stage, which makes the methods computationally expensive when applied to a large number of extracted features. In order to address such challenge, this paper proposes a Saliency-Informed Spatio-Temporal VLAD (SST-VLAD) approach which selects the extracted features corresponding to small amount of videos in the data set by considering both the spatial and temporal video-wise saliency scores; and the same extension principle has also been applied to the FV approach. The experimental results indicate that the proposed feature encoding schemes consistently outperform the existing ones with significantly lower computational cost.
Publication
Saliency-Informed Spatio-Temporal Vector of Locally Aggregated Descriptors and Fisher Vectors for Visual Action Recognition by Zhiguang Liu, Liuyang Zhou, Howard Leung and Hubert P. H. Shum in 2018
Proceedings of the 2018 British Machine Vision Conference Workshop on Image Analysis for Human Facial and Activity Recognition (IAHFAR)
Links and Downloads






Similar Research