DSPP: Deep Shape and Pose Priors of Humans
Abstract
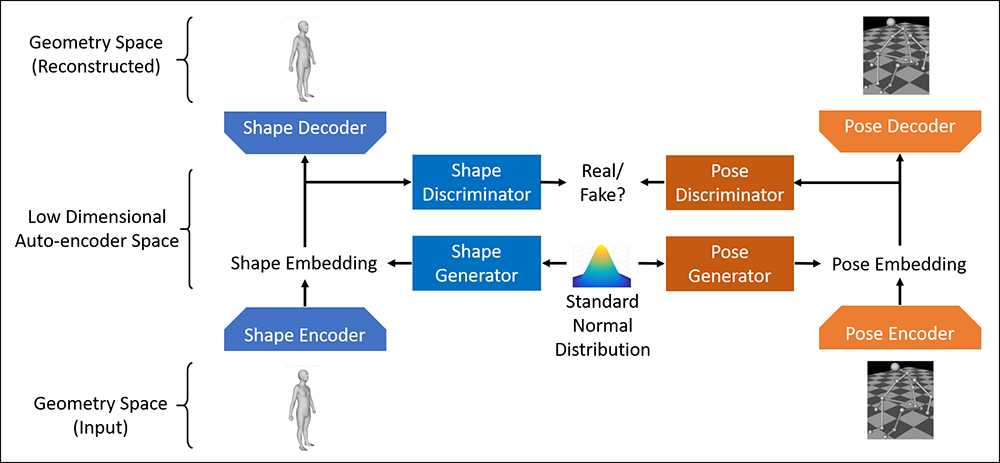
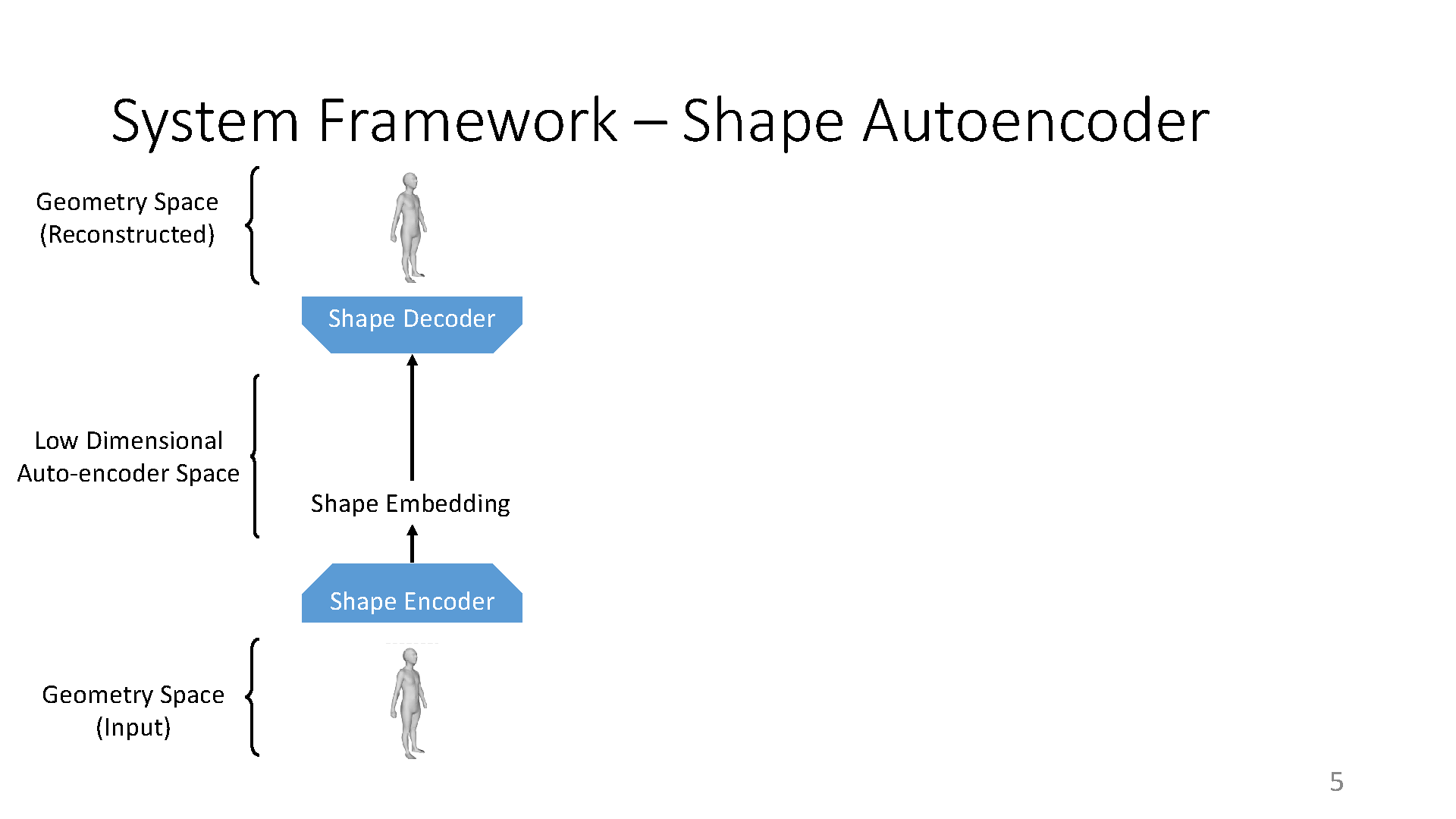
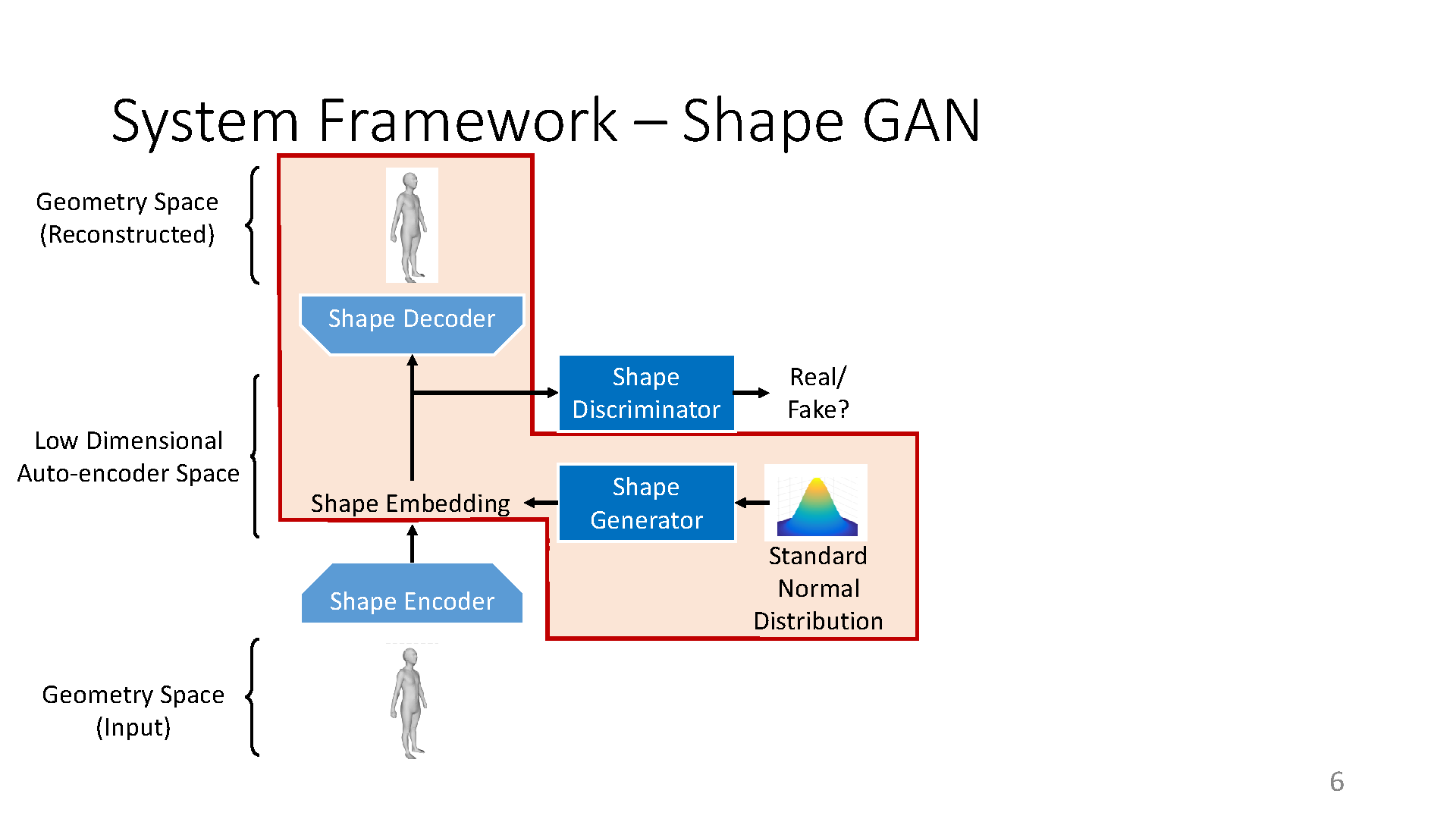
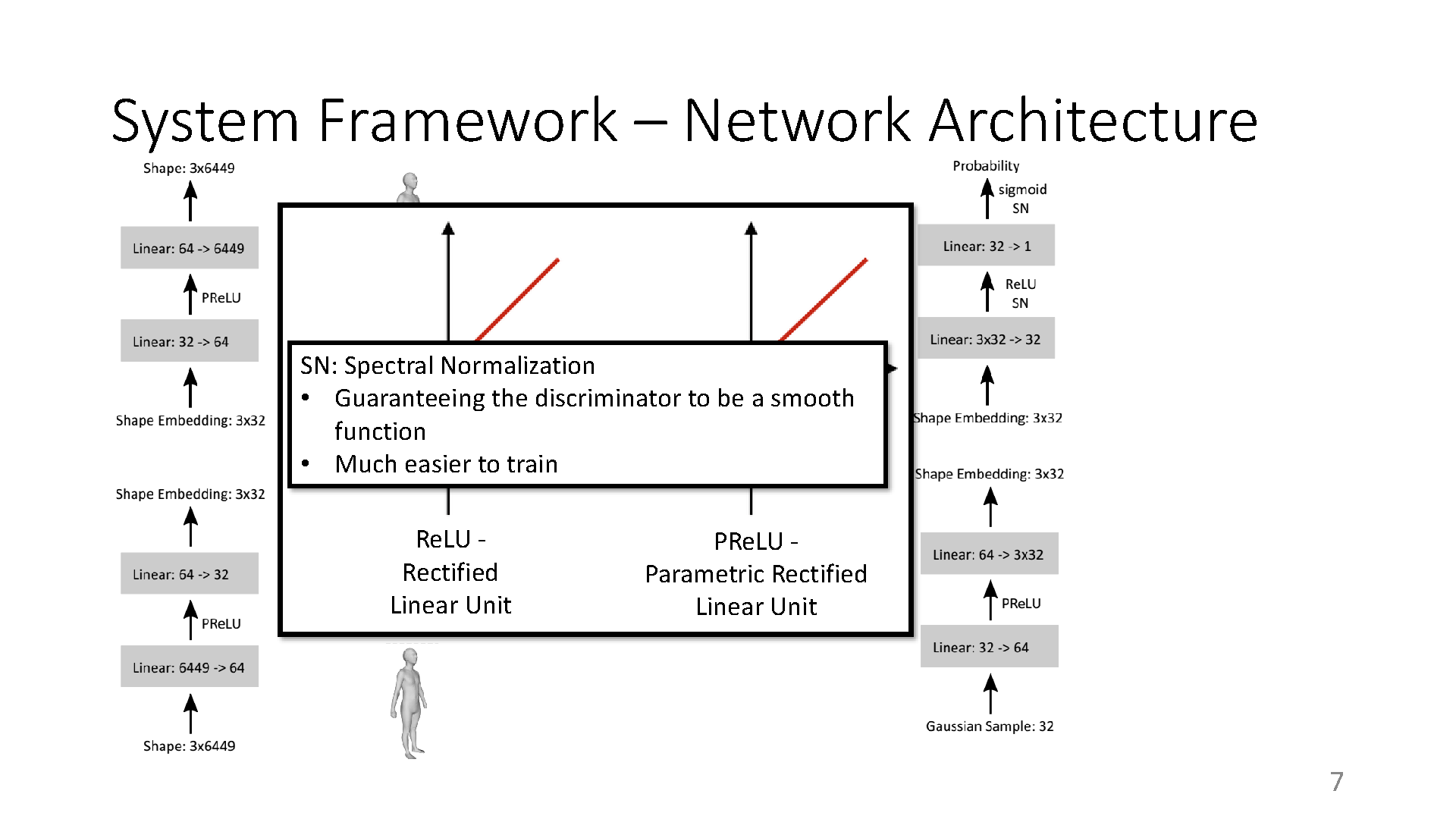
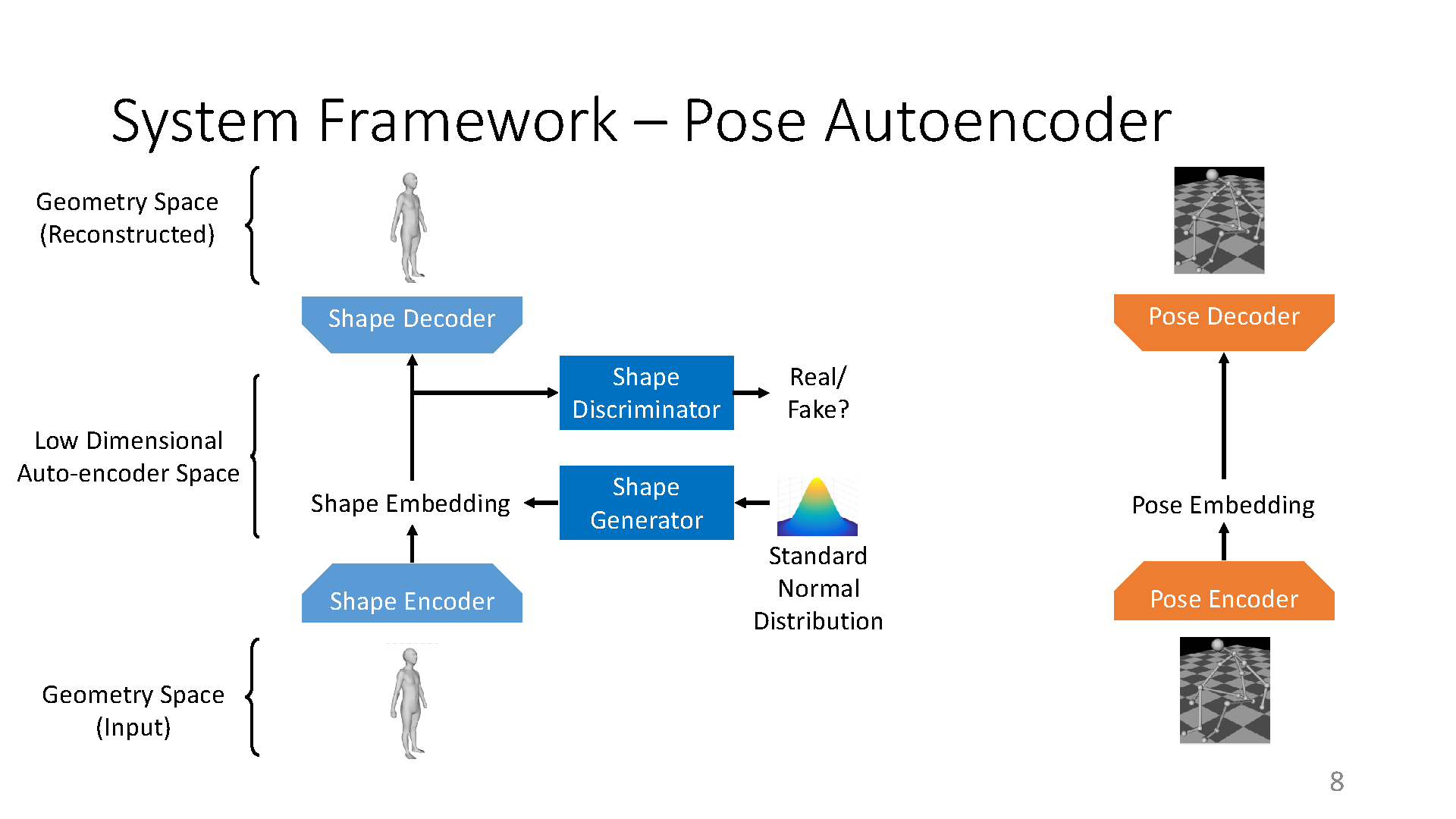
The prior knowledge of real human body shapes and poses is fundamental in computer games and animation (e.g. performance capture). Linear subspaces such as the popular SMPL model have a limited capacity to represent the large geometric variations of human shapes and poses. What is worse is that random sampling from them often produces non-realistic humans because the distribution of real humans is more likely to concentrate on a non-linear manifold instead of the full subspace. Towards this problem, we propose to learn human shape and pose manifolds using a more powerful deep generator network, which is trained to produce samples that cannot be distinguished from real humans by a deep discriminator network. In contrast to previous work that learn both the generator and discriminator in the original geometry spaces, we learn them in the more representative latent spaces discovered by a shape and a pose auto-encoder network respectively. Random sampling from our priors produces higher-quality human shapes and poses. The capacity of our priors is best applied to applications such as virtual human synthesis in games.
Publication
DSPP: Deep Shape and Pose Priors of Humans by Jacky C. P. Chan, Hubert P. H. Shum, He Wang, Li Yi, Wei Wei and Edmond S. L. Ho in 2021
Proceedings of the 2019 International Conference on Motion, Interactions and Games (MIG)
Links and Downloads





















YouTube
Similar Research